今月から東京リージョンでもDynamoDBのエクスポートが利用できるようになりました!
【AWS発表】DynamoDBテーブルのクロスリージョンエクスポート&インポート
DynamoDBのバックアップ
DynamoDBはとても便利ですが、これまでデータのバックアップを簡単に取る方法がありませんでした。
DynamoDBのデータは複数リージョンにまたいで冗長化されているので、データが突然消えてしまうということはまずないと思いますが、操作ミスなどによってデータを削除してしまう危険性はあります。そういうリスクを考えると、定期的なバックアップをとる必要があります。
これまでは、バッチスクリプトを書いて、定期的にDynamoDBのデータをS3に転送することをしていました。それが遂に、東京リージョンでもエクスポート機能が使えるようになり、AWS Management Consoleからポチポチするだけでバックアップが取れるようになりました。
エクスポートの手順
手順は、先に紹介したブログか、次のドキュメントにしたがえば、簡単にできます。
Exporting Data From DynamoDB to Amazon S3
- AWS Management Consoleで、DynamoDBのコンソールを開く
- メニューバーの「Export/Import」ボタンを押して、エクスポート画面を開く
- エクスポートしたいテーブルを全て選択して「Export from DynamoDB」ボタンを押す
- エクスポート先のS3バケットを指定してエクスポートを実行する
簡単そうですね。
エクスポートの実行
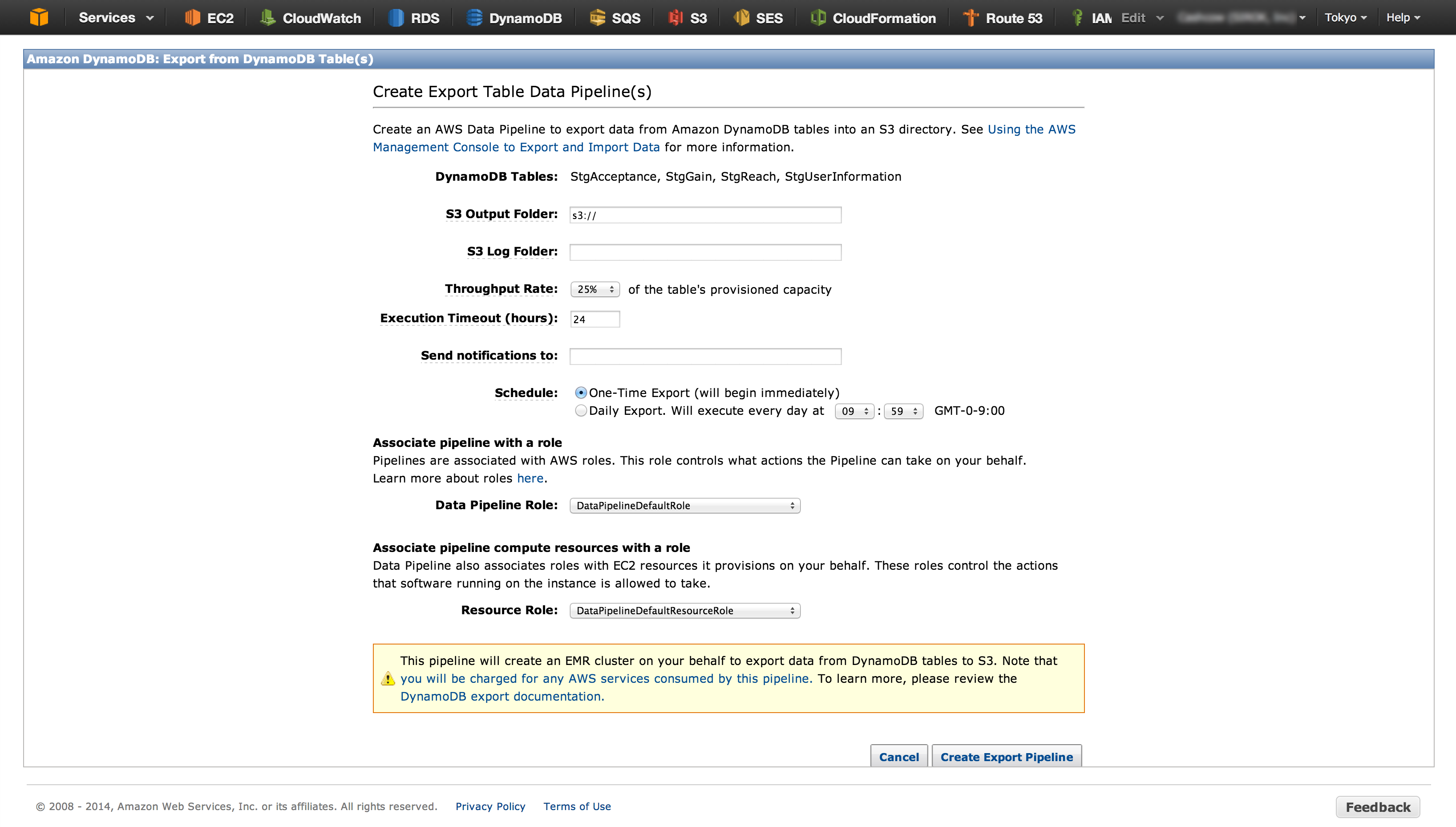
エクスポート画面はこんな感じです。最低限設定しなければいけないのは、出力先のS3のディレクトリだけです。
この手順を実行するには、DataPipelineDefaultRoleとDataPipelineDefaultResourceRoleというIAM Roleを持っている必要があって、もし作っていない場合は先に作っておく必要があります。
手順は、次のページにかかれています。
Prerequisites to Export and Import Data
Elastic MapReduceが起動しない。
このDynamoDBのエクスポート処理は、Amazon Data Pipelineから、Elastic MapReduce(EMR)を起動して実行されます。
はじめてのElastic MapReduceだったのでワクワクしていたのですが、途中でエラーで停止してしまいました。
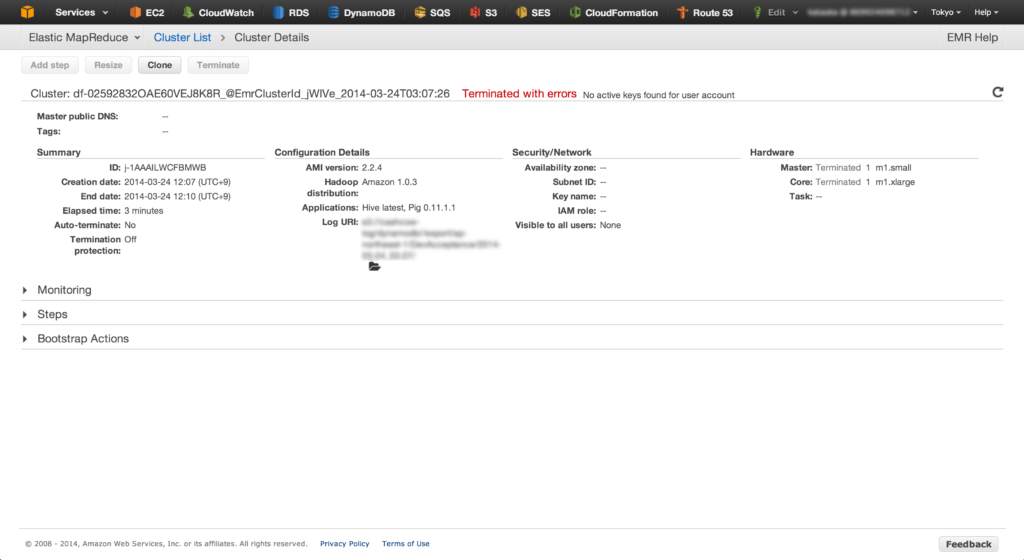
エラーは「有効なキーがない」というものでした。
Terminated with errors: No active keys found for user account
調べてみると、Stack Overflowにもありました。
Amazon Elastic Map Reduce – Creating a job flow
ユーザーアカウントに対して、アクセスキーが作成されていないのが原因らしいです。仕方ないので、アクセスキーを作成すると、無事にEMRを起動することができました。
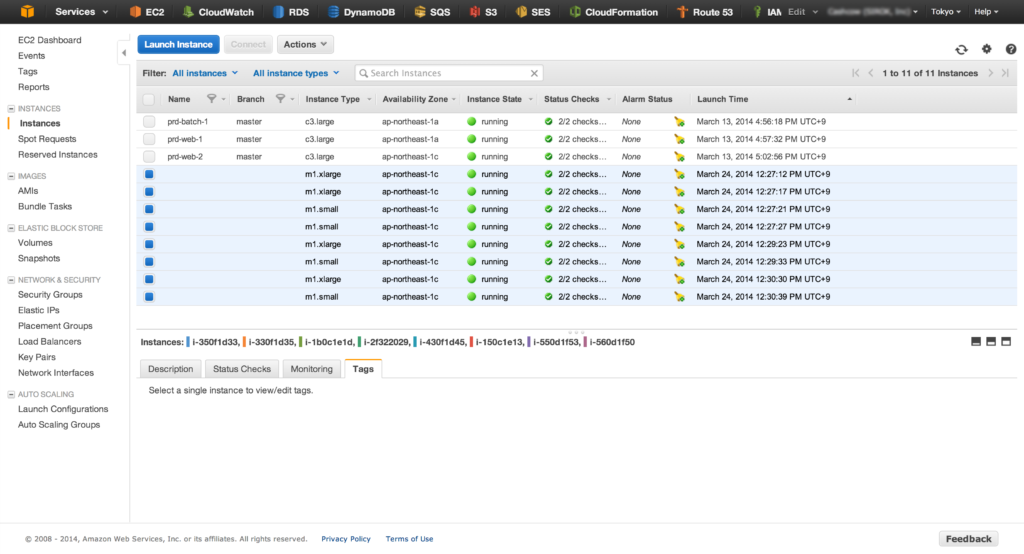
DynamoDBの1テーブルにつき、EMRのジョブが1つ生成され、EC2インスタンスが2台起動し、データをS3に転送していきます。転送が完了すると、起動したEC2インスタンスはシャットダウンされます。
今回作業をしたテーブルは量が多くないので、それほど時間はかからず10分くらいで完了しました。バックアップにかかるコストは、起動したEC2インスタンスの1時間分の料金になりそうです。
便利でした!
プログラムを一切書かなくてもバックアップが取得できてとても便利でした!
テーブルに設定したスループットに対して、バックアップ用に一定量を割り当てる機能もあるので、スループット不足でサービスに影響を与える確率も低そうです。
DynamoDBの画面から設定しますが、実体はAmazon Data Pipelineなので、定期的なバックアップなども設定できて、DynamoDBの導入コストがぐっと下がります。