「クラスタマネージャーApache Mesosを使って、Amazon EC2にクラスタを構築。」で構築したクラスタを使って、Sparkの分散処理を実行してみます。
Apache SparkをAmazon EC2にインスール
今回は、SparkをAmazon EC2のインスタンスにインスールしていきます。やっていることは下記と同じで、ビルド済みのパッケージをダウンロードして配置しているだけです。
高速な分散処理エンジンApache Sparkの操作を対話シェルで試してみる!
cd /tmp
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0-bin-hadoop2.4.tgz
tar xzf spark-*.tgz
rm spark-*.tgz
sudo mv spark-* /opt/spark
これでSparkが配置完了です。
Apache Mesosを利用するためのApache Sparkの設定
Mesosで構築したクラスタを利用するために、Sparkの設定を変更していきます。
spark-env.shに、MESOS_NATIVE_LIBRARYとSPARK_EXECUTOR_URIの環境変数を設定します。
cp /opt/spark/conf/spark-env.sh.template /opt/spark/conf/spark-env.sh
cat << EOT >> /opt/spark/conf/spark-env.sh
export MESOS_NATIVE_LIBRARY=/usr/local/lib/libmesos.so
export SPARK_EXECUTOR_URI=http://d3kbcqa49mib13.cloudfront.net/spark-1.2.0-bin-hadoop2.4.tgz
EOT
spark-defaults.confに、spark.mesos.coarseのプロパティを追加します。
cp /opt/spark/conf/spark-defaults.conf.template /opt/spark/conf/spark-defaults.conf
cat << EOT >> /opt/spark/conf/spark-defaults.conf
spark.mesos.coarse=true
EOT
このspark.mesos.coarseを設定しないと、次のようなエラーが出てタスクが処理されませんでした。
Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory
設定はこれで終わりです。
Apache Mesos上にApche Sparkの起動
インスールが完了したら、Sparkを起動します。
今回もSparkの対話シェルを起動しますが、–masterオプションを指定しています。ここには、「クラスタマネージャーApache Mesosを使って、Amazon EC2にクラスタ構築。」で構築したMesosのURIを指定します。
/opt/spark/bin/spark-shell --master mesos://172.31.1.168:5050/
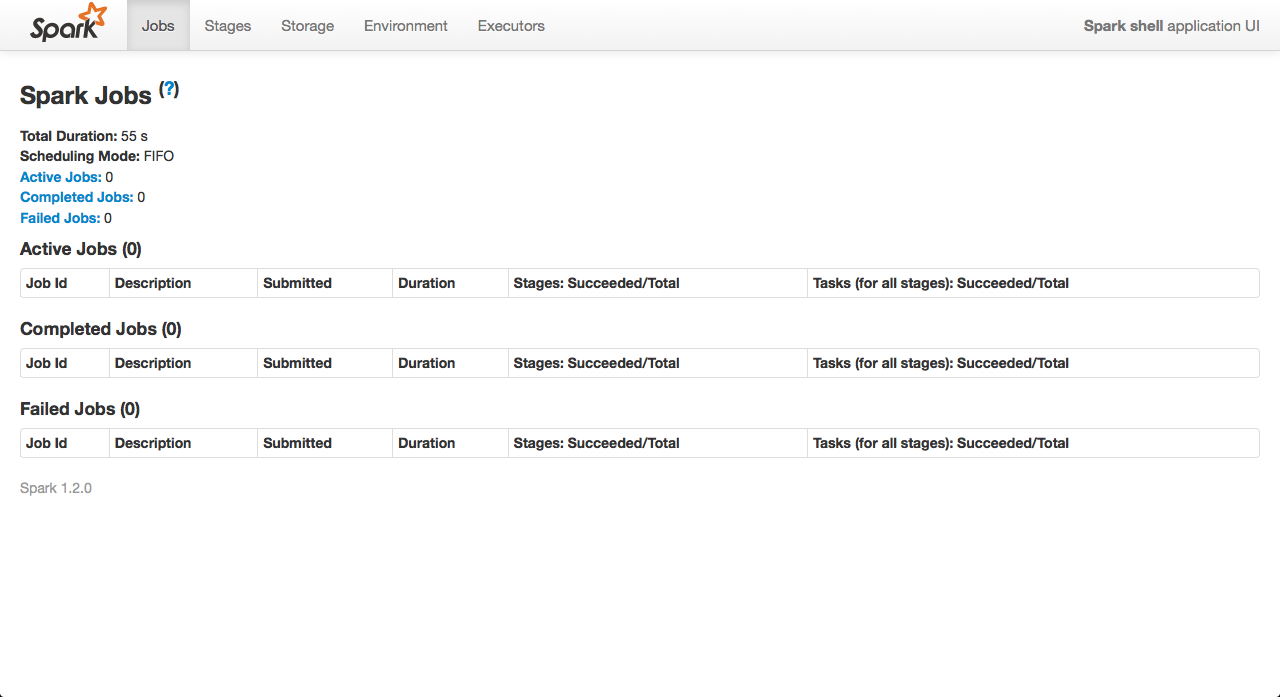
対話シェルが起動して、プロンプトが表示されたら、4040ポートでブラウザを開くと、Sparkの管理画面を見ることができます。

そして、5050ポートでMesosの管理画面を開くと、FrameworksのメニューにSpark shellが認識されているのが分かります!

SparkとMesosの連携が確認できました!
クラスタ2台の構成にしてSparkのコマンドを実行すると、次のようにタスクが分散されて実行されるのを見ることができます。

Mesosで構築したクラスタ上でSparkの動作が確認できました!
動作が確認できたところで、分散によって処理が高速化されるのかが気になってきます。
ノード数を変えて処理時間を比較
シンプルな問題として、1〜10億までの総和を計算してみます。
まず、クラスタのノード数を1台にして、実行。総和の計算には、39.6秒かかりました。
scala> sc.parallelize(1 to 1000000000).sum()
// ...(略)...
15/01/05 11:24:03 INFO DAGScheduler: Job 8 finished: sum at :13, took 39.586944 s
res6: Double = 5.0000000007595942E17
ノードを追加して、2台にします。19.7秒で、約半分の時間になりました!
scala> sc.parallelize(1 to 1000000000).sum()
// ...(略)...
15/01/05 11:20:54 INFO DAGScheduler: Job 6 finished: sum at :13, took 19.719305 s
res6: Double = 5.0000000007595942E17
更にノードを1台追加して、3台にしました。総和の計算時間は、14.5秒。1台の時に比べて、約3倍の速度になりました。
scala> sc.parallelize(1 to 1000000000).sum()
// ...(略)...
15/01/05 11:26:38 INFO DAGScheduler: Job 9 finished: sum at :13, took 14.491517 s
res6: Double = 5.0000000007595942E17
ノード数に比例して高速化する様子を確認することができました!
| ノード数 | 処理時間 |
| 1台 | 39.6 sec |
| 2台 | 19.7 sec |
| 3台 | 14.5 sec |
実際に使うときは、こんな分散しやすい問題ばかりではないと思いますが、それでも十分に高速化な処理が期待できそうです。

コメント
[…] Cassandra Java Driverで、JavaからCassandraを操作する。 […]