
この本を読みました!
Elasticsearch実践ガイド
Elasticsearchとは?
Elasticsearchは、「検索サーバ」です。
内部には、Apache Luceneという、検索ライブラリを採用しています。Elasticsearchを全文検索エンジンと呼ぶことが多いですが、全文検索の本体はApache Luceneです。
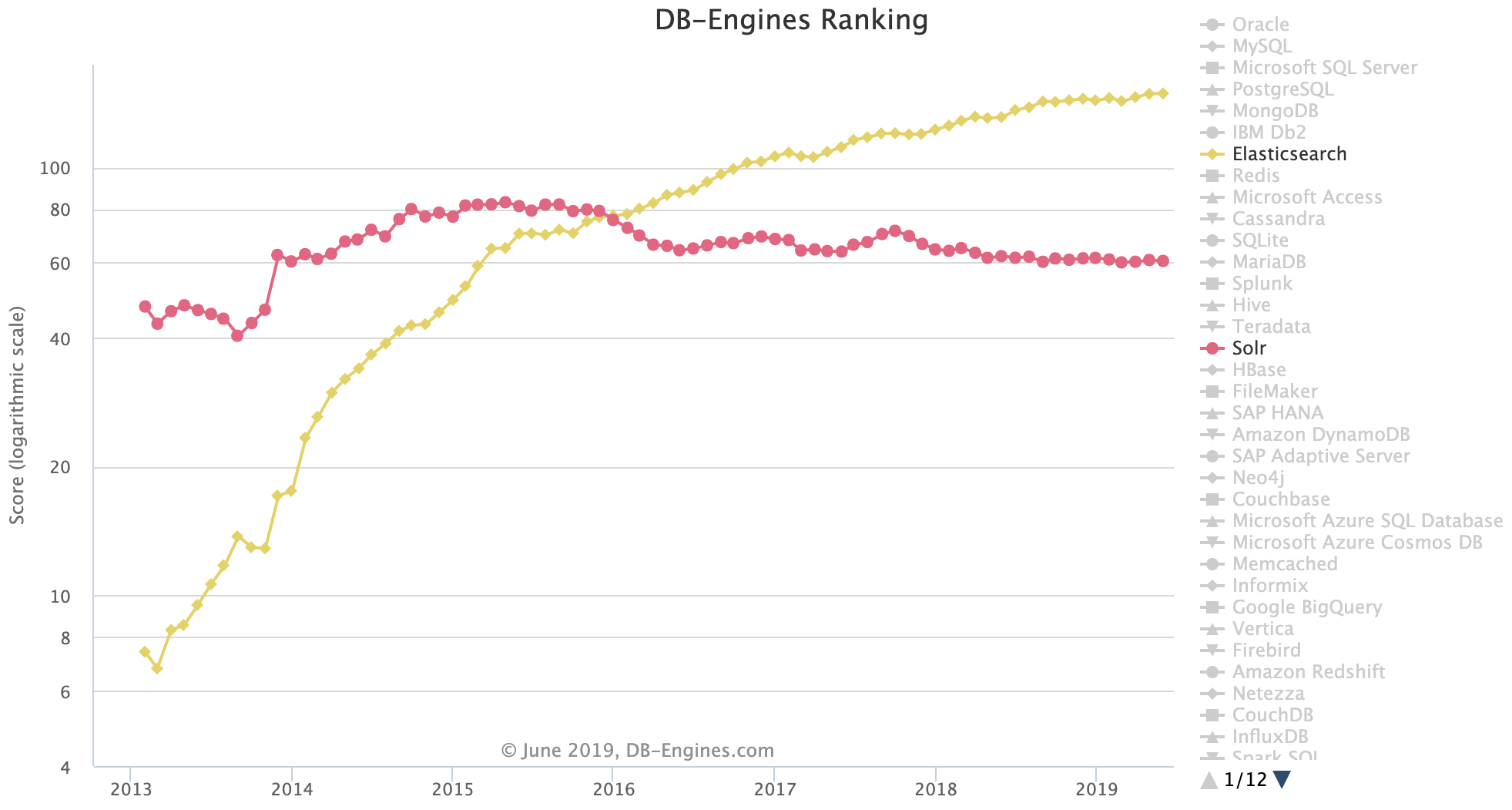
ちなみに、同じように内部にApache Luceneを採用している検索サーバとして、Apache Solrというものもあります。
Elasticsearchは後発ですが、DB-Engines Rankingによると、2016年ごろにApache Solrを上回っていて、人気が高まっています。
Elasticsearchの特徴は?
Elasticsearchでは、検索自体はApache Luceneに任せていて、Elasticsearch自体は、Luceneを活用するためのサーバとしての役割を担っています。
- 分散配置できる (=高性能・高可用性)
- JSONフォーマットのドキュメント指向DB
- REST APIで操作できる
データが大規模になっても高いパフォーマンスで検索できるように、分散配置ができるようになっていて、JSONフォーマットやREST APIで使いやすく設計されている、というのが特徴です。
Elasticsearchを起動してみる
Elasticsearchを起動して、ドキュメントの追加と検索を試してみます。ドキュメントというのは、Elasticsearchのデータのことで、RDBMSでいうとレコードに相当します。
Dockerイメージがあるので、これを使って、立ち上げてみます。
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.8.1起動したら、ステータスを確認してみます。
$ curl -X GET 'http://localhost:9200/_cat/health'
1561879921 07:32:01 docker-cluster green 1 1 0 0 0 0 0 0 - 100.0%クラスタが「green」となってることが確認できました。
ElasticsearchはREST APIで操作できるので、クライアントツールなどをインストールしなくても操作することができます。
ドキュメントの登録
さっそくデータを投入してみます。
ドキュメントには、「/{インデックス名}/{タイプ名}/{ドキュメントID}」というパスが割り当てられています。インデックスとタイプは、RDBMSでいう、データベースとテーブルに該当します。
そこにJSON形式のドキュメントをリクエストボディとして、PUTリクエストを送信します。
$ curl -X PUT 'http://localhost:9200/my_index/my_type/1?pretty' -H 'Content-Type: application/json' -d '{"title":"hello world"}'
{
"_index" : "my_index",
"_type" : "my_type",
"_id" : "1",
"_version" : 4,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}無事に登録ができました!
検索を試すために、他にも2件データを入れておきます。
curl -X PUT 'http://localhost:9200/my_index/my_type/2?pretty' -H 'Content-Type: application/json' -d '{"title":"Elasticsearch is the most popular search engine in the world."}'
curl -X PUT 'http://localhost:9200/my_index/my_type/3?pretty' -H 'Content-Type: application/json' -d '{"title":"Hello! My name is katty0324."}'ちなみに、ドキュメントIDを指定せずに、POSTリクエストをすれば、自動的にIDを割り当てて登録してくれます。
検索してみる!
これで3件のドキュメントが追加された状態になります。
| ID | title |
| 1 | hello world |
| 2 | Elasticsearch is the most popular search engine in the world. |
| 3 | Hello! My name is katty0324. |
ここで、titleにhelloを含むドキュメントを検索してみます。
$ curl -X GET 'http://localhost:9200/my_index/my_type/_search?pretty' -H 'Content-Type: application/json' -d '{"query":{"match":{"title":"hello"}}}'
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "my_index",
"_type" : "my_type",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "hello world"
}
},
{
"_index" : "my_index",
"_type" : "my_type",
"_id" : "3",
"_score" : 0.2876821,
"_source" : {
"title" : "Hello! My name is katty0324."
}
}
]
}
}「hello」を含むドキュメントだけが取り出せました!
Elasticsearch面白い!
以上、めちゃくちゃ簡単な例でした。
Elasticsearchはドキュメント指向DBの側面もあるので、構造をもったデータを管理して、検索することができます。クエリは、JSON形式で複雑な条件を表現することができます。
RDBMSで検索機能を組み立てようと思うと、パフォーマンスの課題が出てくることが多いと思います。Elasticsearchでは、転置インデックスによる検索に最適化されたデータ構造に加えて、シャーディングによる性能向上ができるので、パフォーマンス要件を満たすのも比較的簡単なのではと思います。
使いみちが色々思いつくので、さらに理解を深めていこうと思います!

