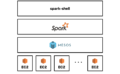
Apache Sparkは、HDFS、Cassandra、HBase、S3など、様々なデータソースを元に分析を実行することができます。
CassandraのデータをApache Sparkで分析したい
以前、Cassandraについてブログを書きました。Cassandra Java Driverを使って、Cassandraからデータを取得し、Javaで分析することができます。
Cassandra Java Driverで、JavaからCassandraを操作する。
しかし、データ量が多くなると、処理に時間がかかるのが悩みです。
「Apache Mesosで構築したクラスタ上で、Apache Sparkの分散処理を実行する。」で、Apache Sparkによって分析処理が高速化できることが確認できましたので、これをCassandraのデータでも利用したくなります。
Spark Cassandra Connectorの導入
Datastax社が、Spark用のライブラリを作ってくれていました!

datastax/spark-cassandra-connector
今回は、このライブラリを使って、手元のMac OS X上で、Apache SparkとCassandraの連携を試します。
Spark Cassandra Connectorは、Mavenで導入することができます。
org.apache.spark
spark-core_2.10
1.2.0
org.apache.spark
spark-streaming_2.10
1.2.0
com.datastax.spark
spark-cassandra-connector_2.10
1.1.0
com.datastax.spark
spark-cassandra-connector-java_2.10
1.1.0
実際には依存関係があるので、spark-streaming_2.10とspark-cassandra-connector-java_2.10だけ導入されていれば十分だと思います。
これでライブラリの導入は完了です。プログラムを実装していきます。
Cassandraを元にしたRDDの作成
Datastaxのブログを参考に、Cassandraのデータの分析処理を実装していきます。
Accessing Cassandra from Spark in Java : DataStax
まずは、Cassandraのデータベースから、SparkのRDDを作成します。RDDというのは、Resilient Distributed Datasetの略で、簡単に言うとSparkが扱うデータのまとまりです。
SparkContextの作成については、「Apache SparkをJavaアプリケーションから使う。」の時とほぼ同じですが、設定にspark.cassandra.connection.hostという項目があります。ここにCassandraのコンタクトポイントを指定します。
SparkConf sparkConf = new SparkConf().setAppName("CassandraTest").setMaster("local").set("spark.cassandra.connection.host", "localhost");
SparkContext sparkContext = new SparkContext(sparkConf);
作成されたSparkContextから、Cassandraのキースペースとカラムファミリーを指定して、RDDを作成することができます。
SparkContextJavaFunctions functions = CassandraJavaUtil.javaFunctions(sparkContext);
JavaRDD rdd = functions.cassandraTable("first_keyspace", "first_table");
あとは、このRDD、つまりSparkのデータに対して分析をしていきます。
Apache Sparkの分析の実行
簡単なところでfirst_tableカラムファミリーのレコード数を取得してみます。先ほどのRDDに対して、countメソッドをかけるだけです。
long recordCount = rdd.count();
System.out.println("recordCount: " + recordCount);
結果は、29715レコードとなりました。
recordCount: 29715
結果の確認ために、cqlshから行数を確認してみます。
cqlsh> use first_keyspace;
cqlsh:first_keyspace> select count(*) from first_table limit 30000;
count
-------
29715
(1 rows)
ちゃんと一致しました!
一見いきなりCassandraの全レコードを取得して処理しているように見えるのですが、Sparkは遅延評価なのでそういう心配はありません。
どういうことかというと、必要になったタイミングで処理を実行するような設計になっているので、CassandraのRDDを生成した段階ではまだデータベースへのアクセスはしておらず、countメソッドを実行した段階で必要な処理だけをするようになっています。
Sparkの全体像がだいたい把握できたので、実運用で使えるかを検討していきたいと思います。