最近、規模の大きなデータを、高速に処理する方法を調べています。
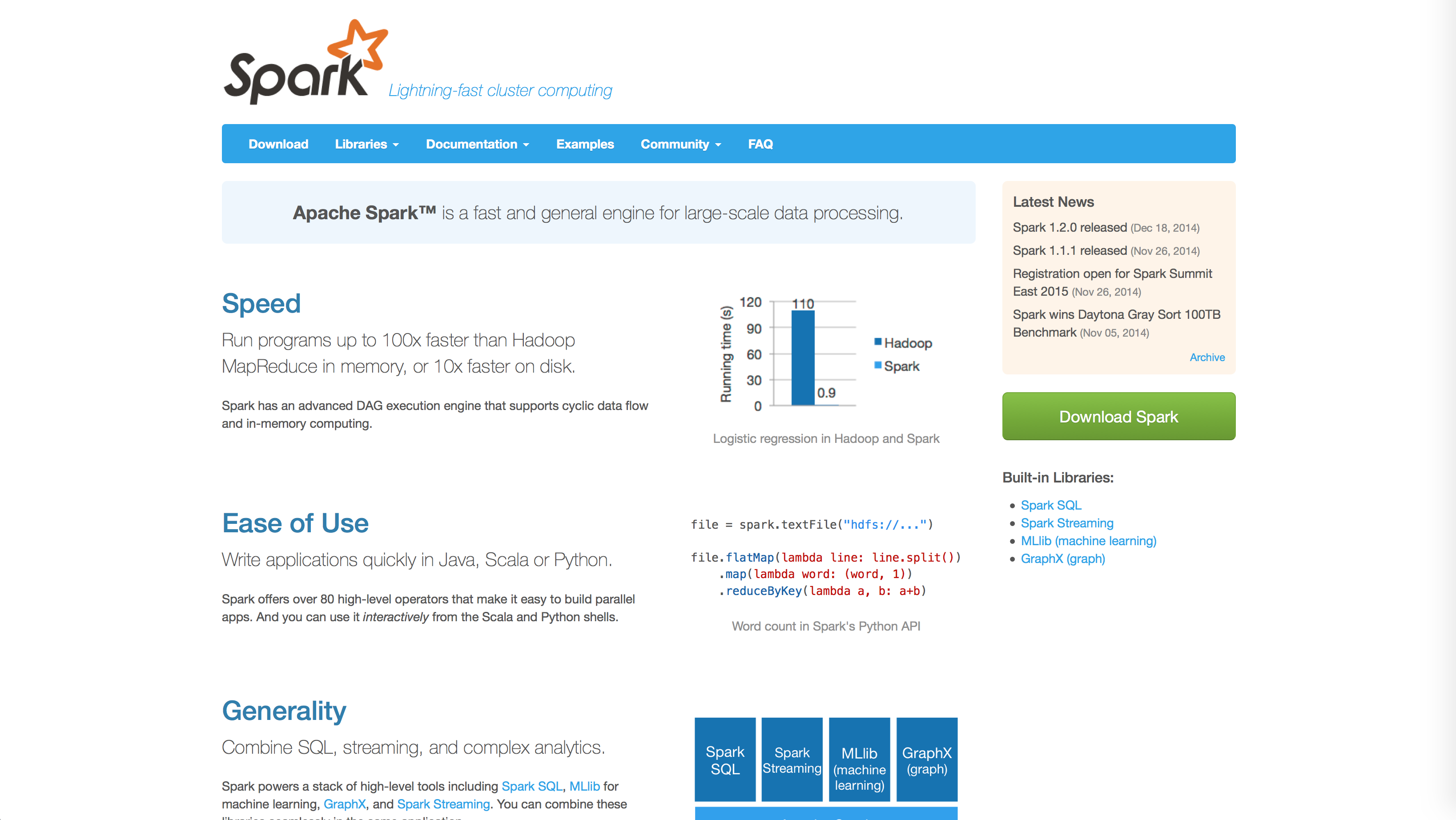
Apache Sparkは高速な分散処理エンジン
「高速に」といっても、「スループットが高い」という意味と、「レスポンスが早い」という意味があります。
「スループットが高い」というのは、一定時間にどれだけたくさんの処理ができるかです。「レスポンスが早い」というのは、処理を要求してから完成までにかかる時間が短いという意味です。
分散処理といえばHadoopが浮かびますが、Hadoopはスループット重視です。レスポンスタイムを重視したい場合には向きません。レスポンスを重視したい場合というのはたとえば、ユーザーからリクエストを受けてすぐに分析結果を返したい場合のような場合です。
Apache Sparkは、レスポンスタイムを重視した分散処理エンジンです。

Apache Spark™ – Lightning-Fast Cluster Computing
先日書いたPrestoもレスポンスタイムを重視した分散処理エンジンです。
分散SQLクエリエンジンPrestoをMac OS Xにインストール
PrestoはSQLクエリを処理することに特化していますが、Sparkは汎用の処理ができるように設計されています。
Apache Sparkのダウンロード
Apache Sparkはオープンソースです。GitHubからソースコードをダウンロードできます。
apache/spark
Sparkは主にScalaで書かれていて、Mavenでビルドすることができます。
mvn -DskipTests clean package
または、Apache Sparkのダウンロードページから、ビルド済みのパッケージをダウンロードすることもできます。ダウンロードは下記から。
Downloads | Apache Spark
今回は試しに、「Apache Spark 1.2.0 Prebuild for Hadoop 2.4」をダウンロードしてみました。
対話シェルの起動
ダウンロードして解凍したら、Sparkシェルを起動してみます。
$ ./bin/spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
# ...(略)...
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25)
Type in expressions to have them evaluated.
Type :help for more information.
# ...(略)...
Spark context available as sc.
scala>
プロンプトが表示されて、入力を受け付ける状態になりました。
「Spark context available as sc.」というメッセージが出ていますが、SparkContextの変数がscという名前で定義されているので、これを利用することができます。
対話シェルにコマンドを打ち込んでみる
Sparkが起動したら、さっそく対話シェルにコマンドを打ち込んでみます。下記のクイックスタートを参考にしています。
Quick Start – Spark 1.2.0 Documentation
ここでは、試しにSparkのREADME.mdを分析してみます。たとえば、README.mdを読み込んで、その行数を数えてみます。
scala> sc.textFile("README.md").count()
res9: Long = 98
結果は98行と出ました。
bashでこのファイルの行数を数えてみると確かに98行のようです。
$ cat README.md | wc -l
98
mapとreduceで複雑な分析をする
countという単純な操作だけでなく、mapメソッドとreduceメソッドで複雑な分析をすることもできます。
たとえば、mapメソッドで、行をスペース区切りにして、1行に含まれる単語数に変換します。そして、reduceメソッドで、1行に含まれる単語数の最大値を求めます。
scala> sc.textFile("README.md").map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)
res10: Int = 14
結果、最大で14単語を含む行があるということが分かりました。
reduceメソッドで用いる関数は、下記のように、java.lang.Mathパッケージをインポートして、置き換えることもできます。
scala> import java.lang.Math
import java.lang.Math
scala> sc.textFile("README.md").map(line => line.split(" ").size).reduce((a, b) => Math.max(a,b))
res11: Int = 14
こちらも結果は14単語です。
これから、Javaアプリケーションでの利用を考えていく予定です。
コメント
[…] 「高速な分散処理エンジンApache Sparkの操作を対話シェルで試してみる!」に続いて、Apache Sparkの操作をJavaからしてみます。 […]
[…] 高速な分散処理エンジンApache Sparkの操作を対話シェルで試してみる! Apache SparkをJavaアプリケーションから使う。 […]
[…] 分散SQLクエリエンジンPrestoをMac OS Xにインストール 高速な分散処理エンジンApache Sparkの操作を対話シェルで試してみる! […]