「高速な分散処理エンジンApache Sparkの操作を対話シェルで試してみる!」に続いて、Apache Sparkの操作をJavaからしてみます。
Apache SparkをJavaから操作
下記のSparkのプログラミングガイドを参考にしました。
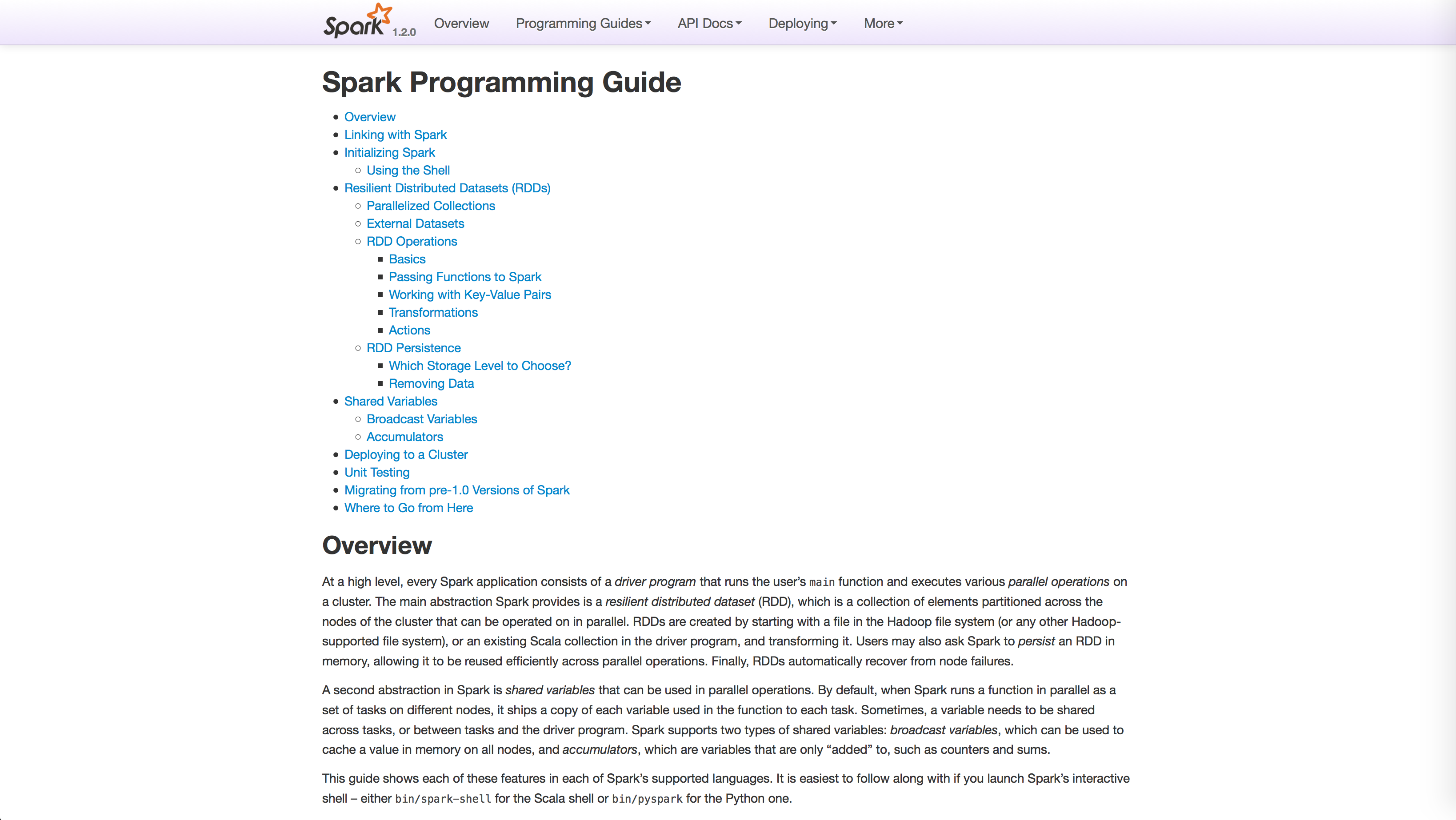
Spark Programming Guide – Spark 1.2.0 Documentation
前回使ったSparkの対話シェルはScalaでしたが、今回は使い慣れているJavaで試してみます。Javaの対話シェルは用意されていませんが、SparkのJavaライブラリは用意されています。
JavaでSparkContextの用意
ライブラリはMavenから導入できます。最新バージョンのSparkで試します。
org.apache.spark
spark-core_2.10
1.2.0
ライブラリが導入できたら、SparkContextを作成します。
「高速な分散処理エンジンApache Sparkの操作を対話シェルで試してみる!」では、対話シェルの起動時点でscという変数にSparkContextが用意されていました。
今回は、プログラムで接続先などを指定して、SparkContextを作成します。クラスタを指定せずにスタンドアローンで使う場合は、setMasterメソッドにはlocalを指定します。
SparkConf sparkConf = new SparkConf().setAppName("test").setMaster("local");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
これで分析の準備ができました。
ファイルの行数を数えてみる
比較しやすいように、前回と同じ分析をしてみます。
まずは、README.mdのファイルの行数を数えます。
long lineCount = sparkContext.textFile("README.md").count();
System.out.println("lineCount: " + lineCount);
Scalaで書いた場合とほぼ同じです。
結果は98行となりました。
lineCount: 98
当然ですが、Scalaの対話シェルで実行した場合と結果も同じになりました。
mapとreduceで複雑な分析をする
続いて、もう少し複雑な処理をしてみます。
次のプログラムは、1行に含まれる単語数の最大値を求めます。ラムダ式が使いたかったので、Java 8を利用しています。
long maxWords = sparkContext.textFile("README.md").map(line -> line.split(" ").length).reduce((a, b) -> Math.max(a, b));
System.out.println("maxWords: " + maxWords);
ラムダ式の表現は、JavaとScalaで少し違いますが、書いていることは同じです。
結果は、14行となりました。
maxWords: 14
こちらも対話シェルで実行した場合と同じになっています。
Sparkの操作のインタフェースは、Java 8のStream APIとほぼ同じなので、Stream APIを使ったことがあれば、すぐに手に馴染むと思います。
コメント
[…] Previous: Apache SparkをJavaアプリケーションから使う。 […]